")
Descripción de la estructura de la JSBD
Otros manuales disponibles:- Manual de uso de motor de base de datos JavascriptSQL
- Manual de uso de la librería JSBD_Conversor
- Manual de uso de la librería JSBD_Indexador
Índice
- Diseño Inicial
- Archivos de definición de la base de datos
- Archivos de tablas
- Archivos de índices
- Archivos de contenido
- Archivos de índices de contenido
I. Diseño Inicial
A continuación se muestra el diagrama de diseño inicial que describe la relación entre los distintos módulos utilizados para el funcionamiento de la base de datos en JavaScript.
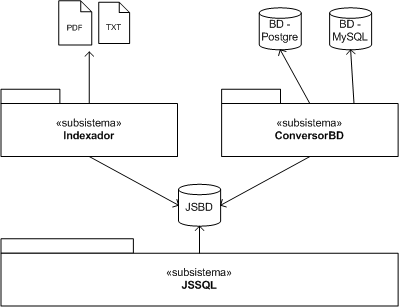
El funcionamiento básico de la base de datos para JavaScript consiste en generar mediante un conversor de bases de datos y un indexador de documentos los archivos de definiciones, tablas, índices y demás componentes de la base de datos JSBD. Luego el motor JSSQL permite acceder de manera eficiente a la base de datos JSBD mediante consultas SQL.
Cada uno de estos componentes o subsistemas están conformados por una o más clases a ser usadas por los desarrolladores. El conversor y el indexador están desarrollados en PHP mientras que el motor JSSQL esta desarrollado íntegramente en JavaScript.
Una vez generada una base de datos JSBD, se pueden realizar consultas SQL mediante el motor JSSQL sin necesidad de acceder a ningún orto motor de bases de datos y sin necesidad de utilizar ningún lenguaje de scripting que funcione del lado del servidor (PHP, ASP, etc.).
La base de datosJSBD es un conjunto de archivos interpretables por JavaScript que contienen la información de la estructura y los datos de la base de datos.
En todas las estructuras de almacenamiento utilizadas se opto por el uso de estructuras JSON (Java Script Object Notation) de manera que cada estructura representa un vector u objeto a ser evaluado por el motor JSSQL.
Los archivos pueden cargarse dinámicamente de manera de optimizar el uso de memoria y los tiempos de respuesta.
II. Archivo de definición de la base de datos
Define la estructura de las tablas de una determinada base de datos. Incluyendo los nombres de las tablas, los nombres de los campos que las componen y los tipos de los mismos. También se detalla información sobre el indexado y paginado de las tablas.
Ejemplo de la estructura de la base de datos neptuno:
neptuno.jsbd
[
{ "tname":"categorias",
"part":0,
"size":8,
"fields":[
{"fname":"idcategoria","ftype":"numeric","findex":false},
{"fname":"nombrecategoria","ftype":"string","findex":false},
{"fname":"descripcion","ftype":"string","findex":false} ]
},
{ "tname":"clientes",
"part":0,
"size":91,
"fields":[
{"fname":"idcliente","ftype":"string","findex":false},
{"fname":"nombrecompania","ftype":"string","findex":false},
{"fname":"nombrecontacto","ftype":"string","findex":false},
{"fname":"cargocontacto","ftype":"string","findex":false},
{"fname":"direccion","ftype":"string","findex":false},
{"fname":"ciudad","ftype":"string","findex":false},
{"fname":"region","ftype":"string","findex":false},
{"fname":"codpostal","ftype":"string","findex":false},
{"fname":"pais","ftype":"string","findex":true},
{"fname":"telefono","ftype":"string","findex":false},
{"fname":"fax","ftype":"string","findex":false} ]
},
(.)
]
La definición de la base de datos se almacena como un vector de objetos del tipo tabla.
Cada objeto del tipo tabla posee los siguientes atributos:
- tname: El nombre de la tabla
- part: La cantidad de registros que componen una página de la tabla (en caso de ser cero la tabla no se particiona).
- size: La cantidad de registros totales de la tabla.
- fields: Un vector de objetos de definición de campos (field).
Cada objeto de tipo campo (field) posee los siguientes atributos:
- fname: Nombre del campo
- ftype: Tipo de campo
Los tipos soportados son los siguientes- numeric: números enteros, o con decimales.
- string: cadenas de caracteres.
- boolean: variables lógicas (true/false).
- date: tiempo expresado en cantidad de milisegundos desde el 01/01/1970.
- link:hace referencia a un documento cuyo contenido ha sido indexado.
- findex: Valor booleano que indica si la tabla posee un índice en dicho campo.
Este vector es cargado en memoria al abrirse la base de datos para ser consultados por el motor JSSQL.
III. Archivos de tablas
Se dispone de un archivo por cada una de las tablas de la base de datos. Representan un vector de dos dimensiones conteniendo los valores de todos los registros de la tabla.
En caso de estar particionada la tabla se cuenta con múltiples archivos asociados, cada uno con una cantidad predefinida de registros.
Ejemplo de la estructura de la tabla categorías:
categorias.jsbd
[
[1,"Bebidas","Gaseosas, café, té, cervezas y maltas"],
[2,"Condimentos","Salsas dulces y picantes, delicias, comida para untar y aderezos"],
[3,"Repostería","Postres, dulces y pan dulce"],
[4,"Lácteos","Quesos"],
[5,"Granos/Cereales","Pan, galletas, pasta y cereales"],
[6,"Carnes","Carnes preparadas"],
[7,"Frutas/Verduras","Frutas secas y queso de soja"],
[8,"Pescado/Marisco","Pescados, mariscos y algas"]
];
IV. Archivos de índices
En caso de que un campo de una tabla se encuentre indexado se genera un vector 'asociativo' que asocia a cada valor existente del campo con un listado de números de registro con dicho valor.
El archivo se nombra como: 'nombre de tabla'_'numero de campo'.ind
Ejemplo de la estructura del índice del campo 8 (pais) de la tabla clientes:
clientes_8.ind
{
"Alemania":[0,5,16,24,38,43,51,55,62,78,85],
"Argentina":[11,53,63],
"Austria":[19,58],
"Bélgica":[49,75],
"Brasil":[14,20,30,33,60,61,66,80,87],
"Canadá":[9,41,50],
"Dinamarca":[72,82],
"España":[7,21,28,29,68],
"Estados Unidos":[31,35,42,44,47,54,64,70,74,76,77,81,88],
"Finlandia":[86,89],
"Francia":[6,8,17,22,25,39,40,56,73,83,84],
"Irlanda":[36],
"Italia":[26,48,65],
"México":[1,2,12,57,79],
"Noruega":[69],
"Polonia":[90],
"Portugal":[27,59],
"Reino Unido":[3,10,15,18,37,52,71],
"Suecia":[4,23],
"Suiza":[13,67],
"Venezuela":[32,34,45,46]
};
Estos índices se cargan en memoria en el momento de apertura de la base de datos.
V. Archivos de contenido
En caso de que un campo sea del tipo 'link' se utiliza el JSBD_Indexador para indexar los contenidos de los documentos referenciados.
Por cada uno de los campos del tipo 'link' se utiliza una carpeta con el nombre de la tabla y el nombre del campo (ej: empleados_notas) donde se almacenan las estructuras relacionadas con el contenido de los enlaces.
Los archivos de contenido representan el contenido textual del archivo indexado, para que pueda ser consultado por el motor JSSQL.
Cada archivo es nombrado con el número de registro asociado.
Ejemplo de contenido de un archivo indexado de la tabla empleados, campo notas
empleados_notas/2.js"Janet es licenciada en Química por la Universidad de Boston (1984). También ha completado un programa de formación en Gestión de minoristas de alimentación. Janet fue contratada como vendedora asociada en 1991 y fue ascendida a representante de ventas en Febrero de 1992";
VI. Archivos de índices de contenido
En caso de que una serie de documentos hayan sido indexados por el indexador JSBD_Indexador se genera un índice invertido que indica los documentos en donde se encontraron cada una de las palabras.
Este índice se particiona por letra de modo que cada archivo contienen la información de las palabras que comienzan con una determinada letra.
Ejemplo de contenido un archivo correspondiente al índice invertido para la letra A del campo notas de la tabla empleados:
Cada archivo es nombrado con el número de registro asociado.
empleados_notas\A.js{
"ADMINISTRACION":[1,5]
,"ALEMAN":[1,7]
,"ALIMENTACION":[2]
,"AMERICANO":[3]
,"ANDREW":[1]
,"ANDREWS":[4]
,"ANGELES":[5]
,"ANNE":[7]
,"ANTES":[8]
,"ARTE":[0]
,"ARTES":[3]
,"ASCENDIDA":[2]
,"ASCENDIDO":[1,4]
,"ASIGNADA":[3]
,"ASISTIDO":[5]
,"ASOCIACION":[1]
,"ASOCIADA":[2]
};
También se crea un archivo con el listado de las palabras frecuentes, estas palabras serán omitidas en las búsquedas:
empleados_notas\Stop.js["UNIVERSIDAD"];